Find duplikerede posteringer i STATA
Her finder du en guide til hvordan du finder duplikerede posteringer i et datasæt i STATA.
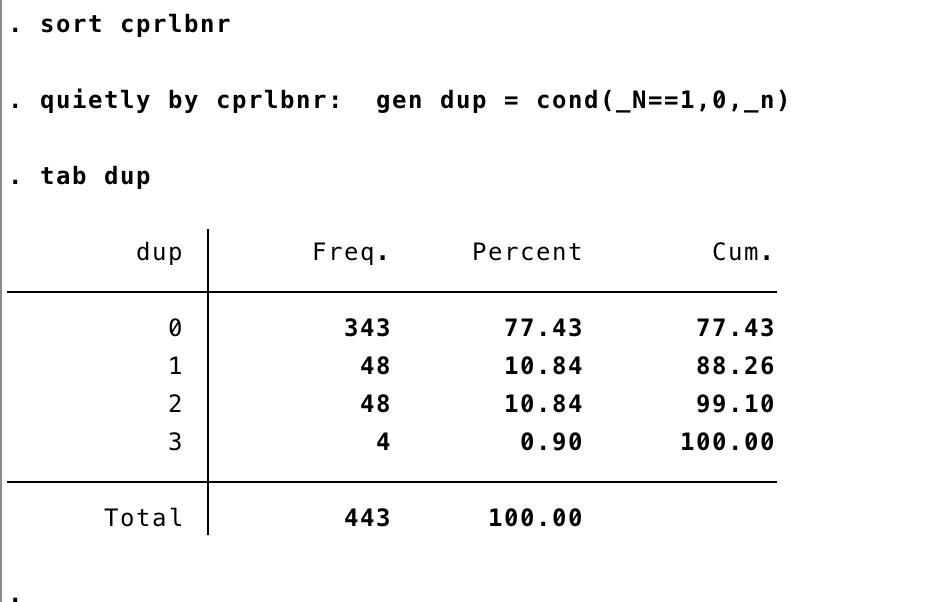
Ved statistik er det ofte nødvendigt at kunne skelne mellem forskellige duplikerede posteringer i et datasæt. Her vil jeg vise hvordan du danner en ny variabel der hedder “dup”. I variablen dup vil vi skrive værdien 0, hvis en postering kun findes én gang. Vi vil skrive 1 hvis den eksisterer flere gange, og dette er 1. gang, 2 hvis det er 2. gang, 3 hvis det er 3. gang etc. Med variablen dup vil vi altså både kunne se om en postering er unik og hvis den ikke er, hvilket nr. den række vi kigger på er.
Hvis du f.eks. har en variabel der hedder “name” og du definerer en postering som unik, hvis værdien i name kun forekommer én gang, kan du skrive følgende:
sort name quietly by name: gen dup = cond(_N==1,0,_n) tab dup
Først sorterer du på variablen name og herefter laver du den nye variabel. Bemærk at _N referer til antallet af observationer i undergruppen for name og _n er observationsnummeret i denne undergruppe. Ved at skrive tab dup får du vist en tabel, der viser hvor mange der findes af hver type.
Hvis vi nu gerne vil definere en unik værdi baseret på flere parametre, skriver vi det i stedet på følgende måde:
sort name age sex address quietly by name age sex address: gen dup = cond(_N==1,0,_n) tab dup
Hvis vi nu gerne vil definere en unik postering baseret på samtlige parametre, kan vi skrive:
unab vlist : _all sort `vlist' quietly by `vlist': gen dup = cond(_N==1,0,_n)
Slet de ikke unikke posteringer
Vi kan nu vælge at slette alle de posteringer, der ikke er unikke med koden:
drop if dup>0
Hvis vi gerne vil slette alle ekstra posteringer, så der kun er de unikke tilbage skriver vi:
drop if dup>1
Dette vil altså både efterlade dem der var unikke, og så den første værdi af alle dem der ikke var unikke. Tilbage har vi kun unikke posteringer.